
https://ieeexplore.ieee.org/document/10243499
JournalのIEEE Transactions on Big Dataである。
Introduction
通常のレコメンドシステムは、つけられた評価などの明確な値をもってして計算して推薦していた。昔は文字についてはそこまで利用できなかったが今はTransformerなどの技術進歩もあって利用できるようになった。一方大量にあるレビューコメントや数値について、ユーザやオーナがすべて目を通すというのは非現実的なものである。
また、レビューコメントの中から「○○については××だった」というような要素の抽出も重要である(アスペクト分析)
しかし、コメントの中ですべての評価点について触れているものはそうそうないわけで、そこがWeakly Supervised Learningでの学習を考えるきっかけに。
先行研究ではWeakly Supervised Learningでは分類タスクに多くつかわれているが、スコアの予測のような回帰タスクへの応用は少ない。
これを踏まえて、Seq2CASEという「コメントと星を入れたら評価スコアを得る」システムをWeakly Supervised Learningで訓練して構築した。訓練に使うのはコメントと星だけ。
Related Works
総合的な評価点をつけるレコメンドシステム
Collaborative Filtering(協調フィルタリング)とは、ユーザ間の行動や嗜好に共通点を見出して推薦を行うシステム。お互いのユーザとアイテムの相互作用を行列補完問題として定式化される。
テキストを用いたレコメンドシステム
明らかにレビューコメントから感情や情報を推測すればいいので、これは自然言語処理を用いることができる。ただし、これは訓練データセットを用意するのが大変で、特に口コミの場合総合点数1つ(しかもかなり離散化された)とコメントしかないので、学習が難しいタイプのラベルである。なので、Weakly supervised Learningの知見を使う。
最近ではTransformerベースで自然言語処理の力を使ったり、Graph Neural Networkの力を使ったりする。だが、DNNベースのものでは再現性やスケールを拡大すると問題に遭う。
Weakly Supervised Framework
学習に使用するのは、「コメント」と「総合評価点数」のペア。
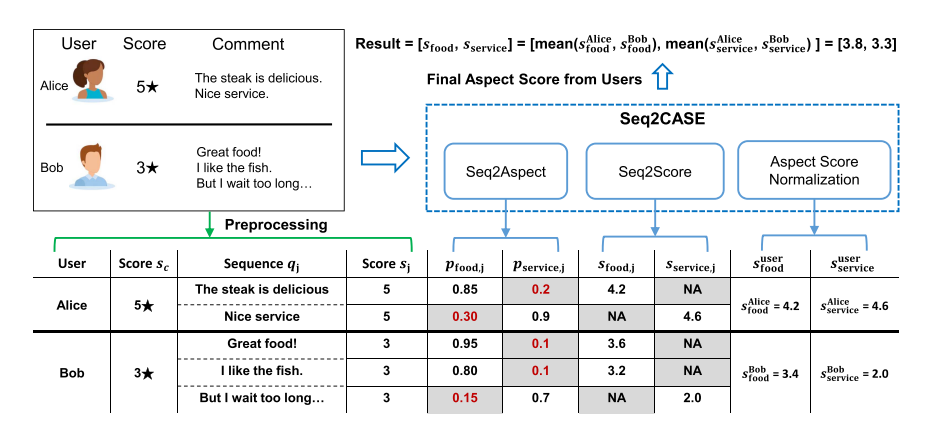
- コメントを各文に分割して、レビュー点数とともにペアにする。
- Seq2Aspect: 各文とレビュー点数のペアを受け取って、各視点ごとの着目度を算出。
- コメントによって言及されてない面の着目度は低く、それ以外は高い。
- Seq2Score: 各文とレビュー点数のペアを受け取って、各視点ごとのスコアを算出。
- Aspect Score normalization: 同じユーザのコメントに含まれるAspect, Scoreについて、各Aspectについて低い着目度があるものを無視し、高い着目度を持つコメントのみを取り入れてコメント全体の総合評価を生成する。
- ここでは、高い着目度のものがもつScoreの平均をとっている。
Weakly Supervised Learningによる学習
言語モデルを使って、各文ごとの埋め込みベクトルをまず取得できる。そして、そこから各Aspect(食事、サービス、立地etc)がわかれば、全体の総合的な評価スコアに加えてこれも学習に使用できる。
ユーザのコメントの中から抽出した文があるとき、以下のようにその文において、Aspectについての着目度を計算するように訓練する。
Seq2Aspect
- 手動で訓練データの中から1000個の頻出語からAspectに関係ありそうな頻出語を選ぶ。
- 言語モデルで、1で選んだ言葉を20個の関連語を探して選択肢を拡張してもらう。
- 例)FoodならDelicious, drinkなどに拡張してもらう。
- 与えられた文の中に単語として存在しているかどうかで着目度が1か0かを決める。これでの訓練を行う。
Seq2Score
各AspectについてのGround-truthラベルはないので、全体的な総合評価をそのままその文のこのAspectについての評価として扱い、訓練する。
注目度と同様に線形で計算する。
そして、回帰タスクなので、MAEで学習する。
Aspect Score normalization
このように計算した、文ごとのAspectの予測はノイズが多いと予想される。なので、例えば0.5を超える着目度を持つ1つのコメントの中の文のみに着目し、それの平均をこのコメント全体の該当Aspectについての評価だとする。
そして、各Aspectについて、毎ユーザごとのレビューコメントの評価の平均をも取ることによって、平均をとることでノイズを減らす。
これはノイズは、コメント固有のもの、Aspect固有のものが各文について独立に起きているという仮定をもとにしているが、実際はもちろんそうではない。だが性能は出ている。
具体的にはどのように訓練するか
コメントの文の選択は実は単語数が2以上20以下でフィルタリングして学習した。
Seq2Caseのレコメンドシステムへの応用
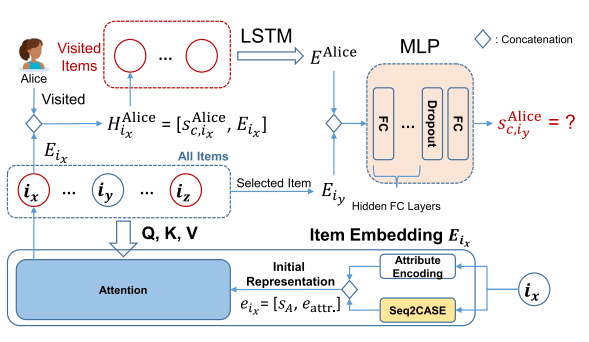
アイテムごとの埋め込み
まずは各アイテム(評価の対象となるもの。例えば商品やレストラン)について、初期の埋め込みベクトルを作成する。これは以下の2部分によってなる。
- 属性の埋め込み。商品ならば所属しているカテゴリ、レストランなら食事の種類などについて、カテゴリごとのものをone-hotベクトル化したを作る。
- 属性として具体的に主観的な評価(ユーザからの点数など)、客観的な評価(店の種類、価格帯、設備場所etc)
- Seq2Caseを用いて、すべてのAspectについての推定したスコアを得る。
- 結合したものを初期の埋め込みとする。
- 各間の類似性を捉えるため、自分にSelf-Attentionを行い、各itemごとにを得る
Userごとの埋め込み
- ユーザがアイテムにつけた評価と、そのアイテムのAttention済の埋め込みを結合させて、ユーザとアイテムの情報をまとめたベクトルを作る。
- これを過去コメントしていた各ItemについてそれぞれLSTMに入れて、そのLSTMにはユーザの嗜好の埋め込みベクトルを得る。
アイテムの推薦
今あるアイテム一覧について、埋め込みがある。その中の各itemの埋め込みとユーザの嗜好の埋め込みをMLPに入力させて、最終的につまり予測されるユーザの嗜好が最も高いものをイチオシ!とする。
MLPには過学習を防ぐためDropoutなどを入れている。
Biasのかかったコメントについて
何かしらの利益を得るために過度に持ち上げる、持ち下げるコメントが成されることはある。これについては重み付けて対処するしかないと考え、このシステムもそれには対応可能。
Experiments
データセットは以下の3つを使用。
- SemEval-2014 全文のアスペクト分類がある。
- TripAdvisor オンラインホテル予約に関するデータセット。
- Yelp-2021, Google Maps NYC GoogleMapみたいな口コミもある地図かな
予測結果は基本的に正解していて、相関係数が0.92-0.96と高かった。
MLPのドロップアウト率は5割が一番良かった。